

データ分析や機械学習を行うとき,データの確認や前処理が必要になることが多いと思います.
この記事では,国税調査のデータ「男女別人口-全国,都道府県(大正9年~平成27年)」を拝借して,データの確認や前処理によく使うpandasの基本的な操作を実行結果とともにまとめていきます.
実行環境
- Windows 11
- Python 3.8.3
- Jupyter Notebook 6.0.3
- pandas 1.4.2
pandasのインポートとデータの読み込み
まずは,e-Statのデータをダウンロードします.

pandasのインポート
import pandas as pdcsvファイルの読み込み
df = pd.read_csv('c01.csv', encoding='shift-jis')データの確認
先頭の行を表示
# 先頭の10行を表示
df.head(10)
末尾の行を表示
# 末尾の10行を表示
df.tail(10)
行数・列数の確認
df.shape# 実行結果
(982, 9) indexの確認
df.index# 実行結果
RangeIndex(start=0, stop=982, step=1)columnの確認
df.columns# 実行結果
Index(['都道府県コード', '都道府県名', '元号', '和暦(年)', '西暦(年)', '注', '人口(総数)', '人口(男)', '人口(女)'], dtype='object')データ型の確認
df.dtypes# 実行結果
都道府県コード object
都道府県名 object
元号 object
和暦(年) float64
西暦(年) float64
注 object
人口(総数) object
人口(男) object
人口(女) object
dtype: object欠損値の確認
# 列ごとに欠損値をひとつでも含むときTrueを返す
df.isnull().any()# 実行結果
都道府県コード False
都道府県名 True
元号 True
和暦(年) True
西暦(年) True
注 True
人口(総数) True
人口(男) True
人口(女) True
dtype: bool欠損値の件数の確認
# 列ごとに欠損値の数を表示
df.isnull().sum()# 実行結果
都道府県コード 0
都道府県名 2
元号 2
和暦(年) 2
西暦(年) 2
注 886
人口(総数) 2
人口(男) 2
人口(女) 2
dtype: int64データの整形
欠損値を含む行を消去
最後の2行は「注」の説明なので,最後の2行を消去し,df_dとします.
df_d = df[:-2]int型に変更
「人口(総数)」「人口(男)」「人口(女)」は数値なので,それぞれint型に変更します.
df_d['人口(総数)'] = df_d['人口(総数)'].astype('int')
df_d['人口(男)'] = df_d['人口(男)'].astype('int')
df_d['人口(女)'] = df_d['人口(女)'].astype('int')# 実行結果
### 省略 #########
ValueError: invalid literal for int() with base 10: '-'「ハイフン(-)」が混ざっていたのでエラーが出ました.
「ハイフン(-)」が混ざっている行を確認します.
print(df_d[df_d['人口(総数)'] == '-'])
print(df_d[df_d['人口(男)'] == '-'])
print(df_d[df_d['人口(女)'] == '-'])# 実行結果
都道府県コード 都道府県名 元号 和暦(年) 西暦(年) 注 人口(総数) 人口(男) 人口(女)
287 47 沖縄県 昭和 20.0 1945.0 1) - - -
都道府県コード 都道府県名 元号 和暦(年) 西暦(年) 注 人口(総数) 人口(男) 人口(女)
287 47 沖縄県 昭和 20.0 1945.0 1) - - -
都道府県コード 都道府県名 元号 和暦(年) 西暦(年) 注 人口(総数) 人口(男) 人口(女)
287 47 沖縄県 昭和 20.0 1945.0 1) 「ハイフン(-)」を含むのは287行目のみなので,この一行は消去し,新たにdf_d2 とします.
df_d2 = df_d.drop(287)消去出来たら,「人口(総数)」「人口(男)」「人口(女)」をint型に変更します.
df_d2['人口(総数)'] = df_d2['人口(総数)'].astype('int')
df_d2['人口(男)'] = df_d2['人口(男)'].astype('int')
df_d2['人口(女)'] = df_d2['人口(女)'].astype('int')確認すると,int32型に変更できたことが分かります.
df_d2.dtypes# 実行結果
都道府県コード object
都道府県名 object
元号 object
和暦(年) float64
西暦(年) float64
注 object
人口(総数) int32
人口(男) int32
人口(女) int32
dtype: object並び替え
# 「人口(総数)」の昇順で並び替え(ascending=Trueで降順)
df_d2.sort_values(by='人口(総数)', ascending=False)
要約統計量と相関
要約統計量
列ごとの要約統計量を表示します.表示できるのは以下の値です.
- count: 要素の個数
- mean: 算術平均
- std: 標準偏差
- min: 最小値
- 25%: 第一四分位数
- 50%: 中央値
- 75%: 第三四分位数
- max: 最大値
df_d2.describe()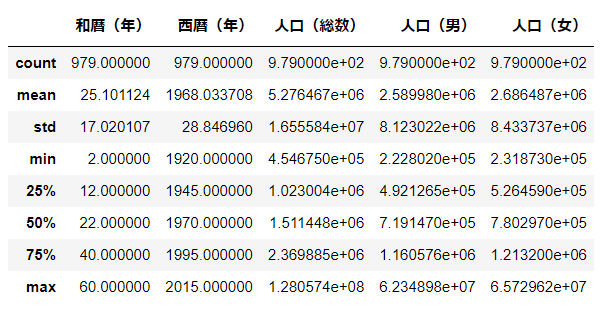
グループ化
グループ化して,平均値などを算出することも可能です.
都道府県別に「人口(総数)」のデータ数,平均,最小値,最大値を表示します.
df_d2[['都道府県名', '人口(総数)']].groupby(['都道府県名']).agg(['count', 'mean', 'min', 'max'])
相関係数
各列間の相関係数を算出します.
df_d2.corr()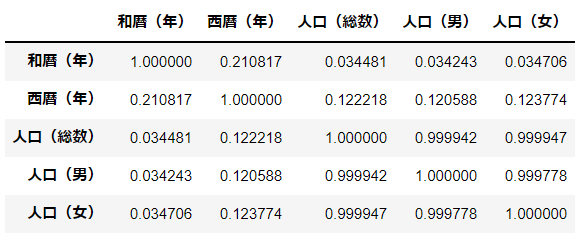
seabornライブラリを利用すれば,ヒートマップも簡単に作成できます.
import seaborn as sns
corr = df_d2.corr()
sns.heatmap(corr)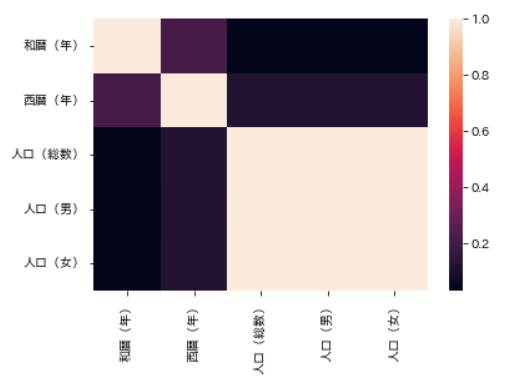
ダミー変数
機械学習などで,質的変数を説明変数として使うときに,ダミー変数化を行うことがあります.
今回は,「元号」をダミー変数に変換してみます.
pd.get_dummies(df_d2['元号'])
「元号」が「大正」「昭和」「平成」の3つに分割され,ダミー変数化出来ていることが分かります.
おわりに
この記事では,データの確認や前処理によく使うpandasの基本的な操作をまとめました.
今回紹介したのはpandasの機能のほんの一部なので,他の機能が気になる方は公式のAPIリファレンスなどを参考にしてみてください.


